|
This page last changed on Mar 19, 2008.
eDocs Home > BEA AquaLogic Data Services Platform Documentation > Data Services Developer's Guide > Contents How To Create a Physical Data Service from a Delimited FileSpreadsheets offer a highly adaptable means of storing and manipulating information, especially information which needs to be changed quickly. You can easily turn such spreadsheet data into a data services.
Spreadsheet documents are often referred to as CSV files, standing for comma-separated values. Although CSV is not a typical native format for spreadsheets, the capability to save spreadsheets as CSV files is very common. You can use the the physical data service creation wizard to:
Physical Data Service Creation WizardThe following topics cover the actions necessary to create physical data services from delimited files: Setting Up the Physical Data Service Creation WizardPhysical data services are created using a wizard. Physical Data Service Creation Wizard
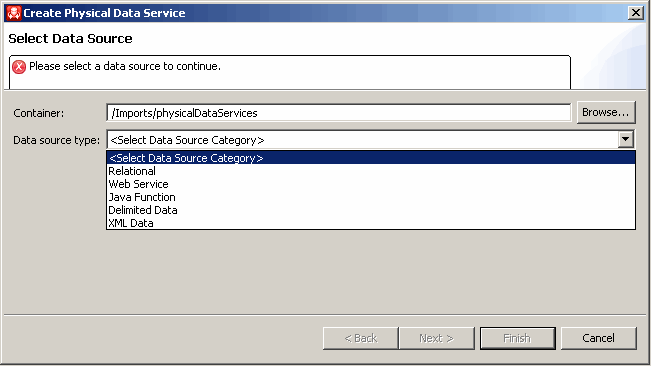
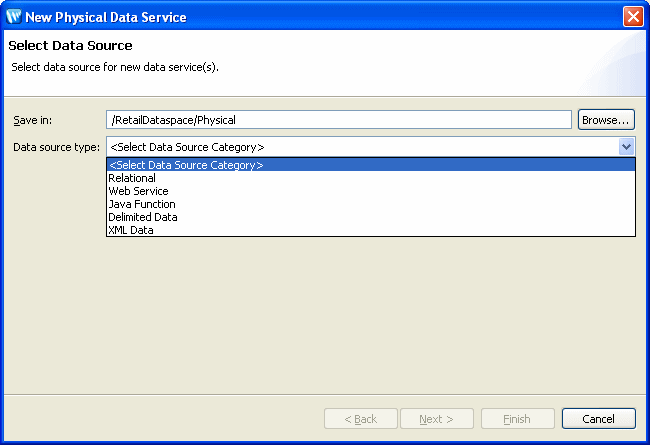
Starting the WizardTo start the physical data service creation wizard:
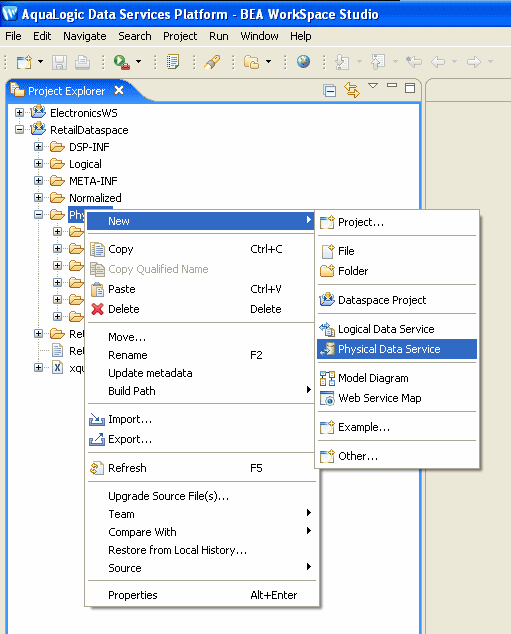
Creating a New Physical Data Service
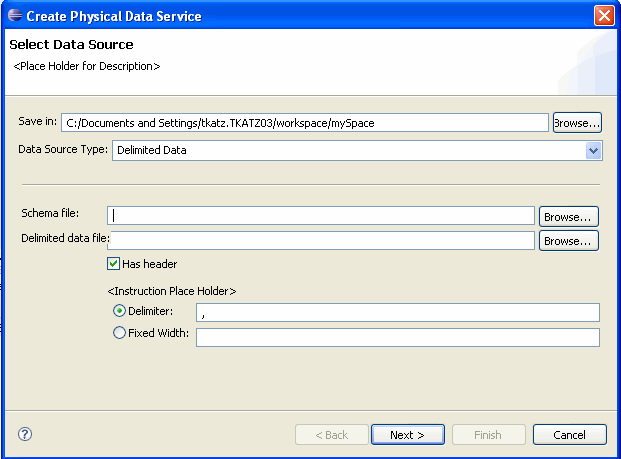
Specifying Delimited File InformationA Library data service based on delimited data requires:
Import Delimited File Data Wizard
The schema and data file must be available in your dataspace. Providing a Document Name, a Schema Name, or BothThere are several approaches to developing metadata around delimited information, depending on your needs and the nature of the source.
Locating the CSV FileUsing the import wizard you can browse to any file in your project. You can also import data from any CSV file on your system using an absolute path prepended with: file:///
For example, on Windows systems you can access an XML file such as Orders.xml from the root C: directory using the following URI: file:///<c:/home>/Orders.csv
On a UNIX system, you would access such a file with the URI: file:///<home>/Orders.csv
Import Delimited Data Options
Supported DatatypesThe following datatypes are supported for delimited file metadata import operations: XMLSchemaType.BASE64BINARY XMLSchemaType.BOOLEAN XMLSchemaType.DATE XMLSchemaType.DATETIME XMLSchemaType.DECIMAL XMLSchemaType.DOUBLE XMLSchemaType.FLOAT XMLSchemaType.INT XMLSchemaType.INTEGER XMLSchemaType.LONG XMLSchemaType.STRING XMLSchemaType.SHORT Additional Considerations
Setting Properties for New Library Functions
Use the Review New Data Service Operations page to:
The root element, which is read only, is also displayed. Verifying Data Service CompositionOn the Review New Data Service(s) page you can set, confirm or, optionally, change suggested data service names depending on the type of physical data service you are creating. Default Physical Data Service NamesThe nominated name for a new data service is, wherever possible, the same as the source object name. In some cases, however, names are adjusted to conform with XML naming conventions.
About Automatic Data Service Name ChangesName conflicts occur when there is a data service of the same name present in the target directory. Name conflicts are highlighted in red. There are several situations where you will need to change the name of your data service:
Data services always have the file extension: .ds |
| Document generated by Confluence on Apr 28, 2008 15:54 |